
AI寒武纪@老虎证券
Diffusion models虽然在生成式 AI 领域混得风生水起,但采样速度慢一直是它的硬伤。要走几十步甚至几百步才能生成一张图片,效率低到让人抓狂!
虽然也有一些蒸馏技术,例如直接蒸馏、对抗蒸馏、渐进式蒸馏和变分分数蒸馏(VSD),可以加速采样,但它们都有各自的局限性,例如计算成本高、训练复杂、样本质量下降等现在,OpenAI 推出了全新的 sCM 模型,只需两步采样,速度提升 50 倍,性能直逼甚至超越扩散模型
sCM作为其前期一致性模型研究的延续和改进,简化了理论框架,实现了大规模数据集的稳定训练,同时保持了与领先扩散模型Diffusion models 相当的样本质量,但仅需两步采样即可完成生成过程,OpenAI同时发布了相关研究论文

sCM是什么?
sCM 和 Diffusion Models 不是完全不同的两种模型,sCM 实际上是基于扩散模型的一种改进模型
更准确地说,sCM 是一种一致性模型 (Consistency Model),它借鉴了扩散模型的原理,并对其进行了改进,使其能够在更少的采样步骤下生成高质量的样本
sCM 的核心是学习一个函数 fθ(xt, t),它能够将带噪声的图像 xt 映射到其在 PF-ODE 轨迹上的下一个时间步的清晰版本。这个过程并不是一步到位地去除所有噪声,而是根据 PF-ODE 的方向,将图像向更清晰的方向移动一步。在两步采样的情况下,sCM 会进行两次这样的映射,最终得到一个相对清晰的图像。
因此,sCM 和扩散模型的关系可以概括为以下几点:
sCM 是基于扩散模型的改进: sCM 依赖于扩散模型的 PF-ODE 来定义训练目标和采样路径,它并不是一个完全独立的模型
sCM 关注单步去噪: sCM 的训练目标是学习一个能够在单个时间步内进行有效去噪的函数,而不是像扩散模型那样进行多步迭代去噪
sCM 采样速度更快: 由于 sCM 只需要进行少量采样步骤(例如两步),因此其采样速度比扩散模型快得多
sCM 并非一步到位: sCM 的单步去噪并非一步到位地去除所有噪声,而是沿着 PF-ODE 的轨迹向更清晰的方向移动一步,多次迭代操作最终达到去噪效果
sCM:两步到位,速度起飞!
OpenAI 基于之前的 consistency models 研究,并吸取了 EDM 和流匹配模型的优点,提出了 TrigFlow,一个统一的框架。这个框架牛逼的地方在于,它简化了理论公式,让训练过程更稳定,还把扩散过程、扩散模型参数化、PF-ODE、扩散训练目标以及 CM 参数化都整合成更简单的表达式了!这为后续的理论分析和改进奠定了坚实的基础
基于 TrigFlow,OpenAI 开发出了 sCM 模型,甚至可以在 ImageNet 512×512 分辨率上训练 15 亿参数的模型,简直是史无前例!这是目前最大的连续时间一致性模型!
sCM 最牛逼的地方在于,它只需两步采样,就能生成与扩散模型质量相当的图像,速度提升 50 倍!例如,最大的 15 亿参数模型,在单个 A100 GPU 上生成一张图片只需 0.11 秒,而且还没做任何优化!。

取样时间在单个 A100 GPU 上测量,批量大小 = 1
sCM 到底有多强?
OpenAI 用 FID (Fréchet Inception Distance 它是一种用于评估生成模型生成图像质量的指标)分数(越低越好)和有效采样计算量(生成每个样本所需的总计算成本)来评估 sCM 的性能。结果显示,sCM 两步采样的质量与之前最好的方法相当,但计算量却不到 10%!
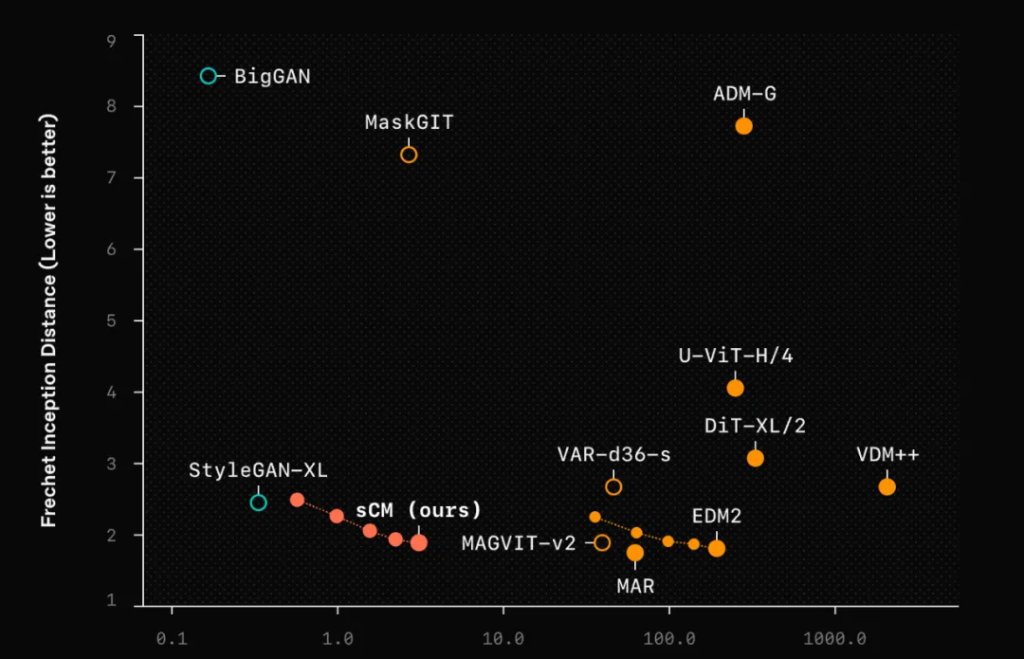
在 ImageNet 512×512 上,sCM 的 FID 分数甚至比一些需要 63 步的扩散模型还要好!在 CIFAR-10 上达到了 2.06 的 FID,ImageNet 64×64 上达到了 1.48,ImageNet 512×512 上达到了 1.88,与最好的扩散模型的 FID 分数差距在 10% 以内.
sCM 的核心改进:
除了 TrigFlow 框架,sCM 还引入了以下几个关键改进,以解决连续时间一致性模型训练不稳定的问题:
改进的时间条件策略(Identity Time Transformation): 使用 Cnoise(t) = t 而不是 Cnoise (t) = log(σα tan(t)),避免了当 t 趋近于 T 时出现的数值不稳定问题
位置时间嵌入 (Positional Time Embeddings): 使用位置嵌入代替傅里叶嵌入,避免了傅里叶嵌入带来的不稳定性
自适应双归一化 (Adaptive Double Normalization): 解决了 AdaGN 层在 CM 训练中带来的不稳定性问题,同时保留了其表达能力
自适应权重 (Adaptive Weighting): 根据数据分布和网络结构自动调整训练目标的权重,避免了手动调参的麻烦
切线归一化/裁剪 (Tangent Normalization/Clipping): 控制梯度方差,进一步提高训练稳定性
JVP 重新排列 (JVP Rearrangement) 和 Flash Attention 的 JVP 计算: 提升了大规模模型训练的数值精度和效率
渐进式退火: 让训练过程更稳定,更容易扩展到大规模模型
扩散微调和切线预热: 通过从预训练的扩散模型进行微调和逐步预热切线函数的第二项,进一步加速收敛并提高稳定性
sCM 的工作原理:
sCM 模型的核心思想是一致性,它试图让模型在相邻时间步的输出保持一致。通过学习 PF-ODE 的单步解,sCM 可以直接将噪声转换成清晰的图像,一步到位!
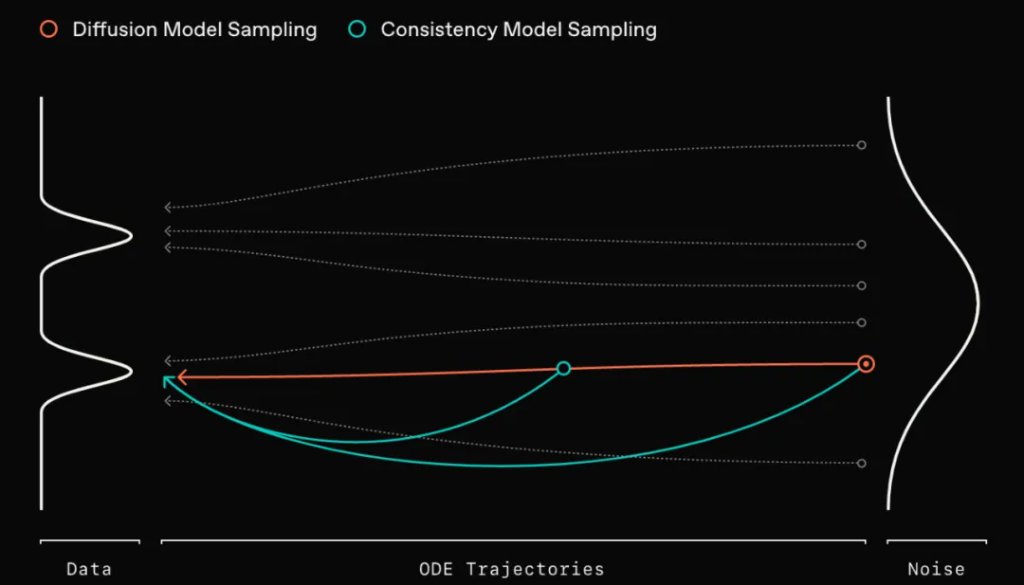
上图中的路径形象地说明了这一差异:蓝线表示扩散模型的渐进采样过程,而红色曲线则表示一致性模型更直接、更快速的采样过程。利用一致性训练或一致性蒸馏等技术,可以训练一致性模型,使其生成高质量样本的步骤大大减少,这对需要快速生成样本的实际应用非常有吸引力
sCM 模型通过从预训练的扩散模型中蒸馏知识进行学习。一个关键的发现是:
随着模型规模的扩大,sCM 模型的改进程度与“教师”扩散模型的改进程度成正比。具体来说,样本质量的相对差异(用 FID 分数的比率衡量)在几个数量级的模型规模上保持一致,这导致样本质量的绝对差异随着规模的扩大而减小
此外,增加 sCM 的采样步骤可以进一步缩小质量差距。值得注意的是,来自 sCM 的两步样本已经可以与来自“教师”扩散模型的样本相媲美(FID 分数的相对差异小于 10%),而“教师”模型需要数百步才能生成样本
sCM 与 VSD 的比较:
与变分分数蒸馏(VSD)相比,sCM 生成的样本更加多样化,并且在高引导尺度下更不容易出现模式坍塌,从而获得更好的 FID 分数
sCM 的局限性:
最好的 sCM 模型仍然需要预训练的扩散模型来进行初始化和蒸馏,因此在图像质量上与“老师”模型相比还是略逊一筹
FID 分数并不完美,有时候 FID 分数接近并不代表实际图像质量也接近,反之亦然。所以,评估 sCM 的质量还是要根据具体应用场景来判断
one more thing
OpenAI说的很清楚:
We believe these advancements will unlock new possibilities for real-time, high-quality generative AI across a wide range of domains
ChatGPT 11月30就两岁了,Sora还没有落地但开发主管都离职了跑路了,但是sCM的发布说明OpenAI内部还在憋大招,sam altman也在暗示ChatGPT两岁生日该发布点什么,也许就是实时高质量视频生成大杀器sora?
实时高质量视频生成大杀器sora有可能吗?
本站文章欢迎转载,但是必须注明出处“美股投资网meegoo”,并附上本文链接:https://www.meegoo.com/12153.html








