
最近几天,DeepSeek一跃成为AI行业最炙手可热的名字。但与此同时,这也让它成为了舆论的风暴中心,各种关于它的质疑和制裁也随之而来。美国政府、科技巨头和行业专家纷纷对DeepSeek发难,指控它涉嫌 “偷窃数据”。意大利则将它下架。Anthropic的CEO还发了一篇万字长文,要求美国进一步收紧对中国的出口管制。那么我们就一起来看一下,这些指控确有其事吗?整个AI投资又会再次发生改变吗?首先,在前天,彭博就报道称,微软和OpenAI正在调查一个与DeepSeek相关的团体。知情人士透露,微软的安全研究人员在去年秋天发现,一些可能与DeepSeek有关的个人,利用OpenAI的API大量提取数据,然后就马上和OpenAI那边说了。
很快,金融时报就跟进了此事,昨天他们报道称,OpenAI说,已经发现证据表明,DeepSeek 可能使用了 OpenAI 的模型训练自己的产品。这也被称之为蒸馏技术。不过公司拒绝提供进一步细节。
昨天,川普AI和加密货币“沙皇” David Sacks 在接受福克斯新闻采访时也声称,掌握了 “确凿证据”,证明DeepSeek利用蒸馏技术, “窃取” OpenAI的模型输出数据来训练自己的模型。但所谓的证据,他却同样一个字也没公布。不知道是不是直接看了金融时报的报道说事。
然而,AI圈里的人都知道,蒸馏这种AI训练技术很常见,它的做法就是让大模型做老师,由小模型将它提问无数个问题,然后通过这个方法学习。只是在OpenAI的使用条例中,就有一条说,不能用输出的内容来训练AI模型与OpenAI竞争。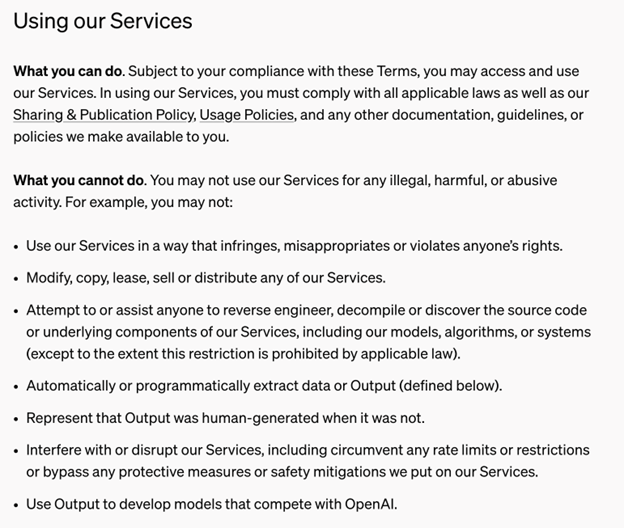

但加州大学伯克利分校的AI博士生Gupta表示,“就算OpenAI想阻止这种行为,难度恐怕不小。初创公司和学术机构利用 ChatGPT 等大模型,来训练自己的模型,已经是行业默认操作。” 他指出,这就等于免费拿到了人类反馈这个最贵的训练环节。OpenAI在最新声明中也明确点明不止是中国在这么做。声明中说,“我们知道中国公司,还有其他国家的团队,一直在尝试蒸馏美国AI巨头的模型。” 于是,他们强调将采取措施 “保护知识产权”,并与美国政府 “密切合作” 来确保AI技术的安全。有意思的是,OpenAI虽然在调查DeepSeek是否存在侵权,但它自己也在和纽约时报等媒体打知识产权的官司。后者表示,OpenAI未经允许就拿了他们生产的内容来训练AI。
面对指控,很多AI圈的专业人士迅速站出来反驳。比如,机器学习专家 Sebastian Raschka 就指出,在AI行业,我们对“蒸馏” 这个词的定义非常宽泛。在DeepSeek R1的论文中,所谓 “蒸馏” 只是他们自己整理的数据集,远非直接克隆OpenAI成果。AI搜索引擎Perplexity的CEO也表示,许多人误以为中国只是’复制’OpenAI的模型,这完全是对AI训练过程的误解。这条帖子还被图灵奖得主杨立昆转发。
在舆论战升级的同时,DeepSeek的在线服务也遭受了大量来自海外IP的大规模暴力破解攻击,试图入侵用户数据。从1月27日开始,DeepSeek的API和网页对话服务频繁出现异常,包括服务性能下降、注册受限等问题。意大利也迅速采取行动,直接将DeepSeek的APP从苹果和谷歌应用商店下架,成为第一个针对DeepSeek采取禁令的西方国家。
最后,Anthropic的CEO 达里奥·阿莫迪发表了一篇万字长文,将这场争议推向新高潮。他认为,DeepSeek的崛起 “充分证明美国应进一步收紧对华芯片出口管制”。这篇文章篇幅很长,但对于我们投资者理解AI的发展趋势,和中美之间AI的竞争尤为重要,阿吉并不打算简单总结。所以我们下面来做一个详细的梳理。最后我们在来说说,这对于整个AI投资的影响。
阿莫迪在文章中列出了AI发展的三大动态。其一是规模法则(Scaling Laws),其二是技术曲线的移动。其三是AI训练的范式变化。我们一个一个来拆解。
对于规模法则,阿莫迪指出,只要条件相同,AI训练规模的扩大就会带来更好的认知能力。比如一个100万美元 训练出的模型,可能只能完成 20% 的重要编程任务,但一个1亿美元训练出的模型,可能能够完成60%。这些差距带来的实际影响巨大,它反映一个规模提升10倍的AI,可能意味着推理能力一下子从本科生跃升到了博士级别。正因为如此,各大AI公司正在大举投资更大规模的训练模型,希望这样能在竞争中保持优势。
对于技术曲线的移动,阿莫迪表示,实际上AI领域的创新从未停歇,每一次新突破都会让AI训练变得更高效。比如优化Transformer架构,让模型计算效率更高。改进底层硬件支持,提升运行速度,或者新一代芯片的出现,直接降低算力成本。这些创新滚动式出现,每一次创新都会推动AI训练的成本效率倍增,让相同资金下的AI性能更强。所以可能过去用1亿美元训练出来的模型,现在只需要5000万,过去1千万的模型,现在只需要500万。
这也是为什么各大公司并不会因为AI变得“更便宜”而减少训练投入,反而会把节省下来的成本继续投入到更智能的模型上。换句话说,当AI成本下降,市场不会减少芯片的使用,而是会加快发展速度。阿莫迪说,2020年,我的团队发布了一篇论文,估计算法的优化会让AI训练成本每年下降 1.68倍。但到2024年,这个数字可能已经达到 4倍 以上。这意味着,如果2023年一个GPT-4级别的模型训练成本是 1亿美元,那么到2024年,训练相同性能的模型可能只需要 2500万美元。
最后一个动态则是AI训练的范式变化。阿莫迪指出,在2020年到23年,AI训练的方式主要是利用互联网海量文本进行训练,并辅以少量额外数据优化。但是随着公开可利用的文本数据消耗殆尽,想要研发出更先进的模型,就需要在AI训练方法上进行底层创新。于是2024年,强化学习开始成为AI优化的新重点,通过强化学习训练 AI自主推理能力。Anthropic、DeepSeek 和 OpenAI 近期发布的AI模型,都大量使用了强化学习来训练链式推理,即模仿人类的思考方式逐步推导。
目前强化学习的这个新范式还在早期,阿莫迪预计未来几年,强化学习训练的资金规模将 从数百万美元增长到数十亿美元。这又回到了规模法则当中去,也就是说上面说三大动态会不停地滚动,如果一方有瓶颈就会在另外两点上寻求突破,直到耗尽红利。
那么在了解完AI发展的三大动态后,阿莫迪就说,从AI训练成本曲线的正常下降趋势来看,DeepSeek-V3的低成本表现是符合 成本下降曲线的,而最近发布的DeepSeek-R1模型有了强化学习微调加持,提升了推理能力,类似于OpenAI的 o1 预览版,但两者都不算是革命性突破。只是因为这种创新成果发生在了中国而不是美国,所以是地缘政治上的重大信号。
于是接下来,阿莫迪就开始阐述,它对于为什么美国要加强芯片出口管制的看法。首先是两个事实,第一个是AI训练成本下降的趋势不会改变,最终美国和中国都会跟上。第二个是,要开发超越人类智能的AI,将需要至少数百万块芯片,耗资数百亿美元,他预计最有可能发生在 2026-2027年。那么既然如此,他认为如果中国能获得数百万颗先进芯片,我们将进入中美“AI双极世界”。而如果中国无法获得,则可能进入单极世界,美国在AI竞争中确立长期优势。因此,唯一能阻止中国获得AI主导权的手段,就是严格执行出口管制。
不知道大家对于这篇文章有什么看法,欢迎在下方留言。综上所述,阿吉认为,DeepSeek不能算是骗局,他只是在现有前沿技术之下,创新了训练方法,优化了模型的推理能力和成本。我还是认可当初梁文峰自己的观点,因为他是站在巨人的肩膀上,所以少走了很多弯路。最终,如果要研发出更智能的模型,还是需要巨额的投入,我们离所谓的通用人工智能AGI也还有很长一段距离,所以在芯片上的投资,算法上的创新等,都不会停止。
如果更进一步说,我会认为技术在高速发展阶段,性能的重要性要远大于成本,我们要先证明能实现,等到能实现之后再去思考如何降本。这就是为什么,我坚持认为DeepSeek这件事不会从根本上影响对于AI的投入。至于各方利用的手段。我认为在科技战略高地的竞争中,各方使出什么手段都有可能,不必做道德评判。只是这些不确定性,的确会给AI基建投资带来更多的波动,也是我们投资者必须要明确的点。
文章来自美投君,作者:阿吉
本站文章欢迎转载,但是必须注明出处“美股投资网meegoo”,并附上本文链接:https://www.meegoo.com/12938.html
